Feature #20878
open")
A new C API to create a String by adopting a pointer: `rb_enc_str_adopt(const char *ptr, long len, long capa, rb_encoding *enc)`
Added by byroot (Jean Boussier) over 1 year ago. Updated over 1 year ago.
Description
Context¶
A common use case when writing C extensions is to generate text or bytes into a buffer, and to return it back
wrapped into a Ruby String. Examples are JSON.generate(obj) -> String, and all other format serializers,
compression libraries such as ZLib.deflate, etc, but also methods such as Time.strftime,
Current Solution¶
Work in a buffer and copy the result¶
The most often used solution is to work with a native buffer and to manage a native allocated buffer,
and once the generation is done, call rb_str_new* to copy the result inside memory managed by Ruby.
It works, but isn't very efficient because it cause an extra copy and an extra free().
On ruby/json macro-benchmarks, this represent around 5% of the time spent in JSON.generate.
static void fbuffer_free(FBuffer *fb)
{
if (fb->ptr && fb->type == FBUFFER_HEAP_ALLOCATED) {
ruby_xfree(fb->ptr);
}
}
static VALUE fbuffer_to_s(FBuffer *fb)
{
VALUE result = rb_utf8_str_new(FBUFFER_PTR(fb), FBUFFER_LEN(fb));
fbuffer_free(fb);
return result;
}
Work inside RString allocated memory¶
Another way this is currently done, is to allocate an RString using rb_str_buf_new,
and write into it with various functions such as rb_str_catf,
or writing past RString.len through RSTRING_PTR and then resize it with rb_str_set_len.
The downside with this approach is that it contains a lot of inefficiencies, as rb_str_set_len will perform
numerous safety checks, compute coderange, and write the string terminator on every invocation.
Another major inneficiency is that this API make it hard to be in control of the buffer
growth, so it can result in a lot more realloc() calls than manually managing the buffer.
This method is used by Kernel#sprintf, Time#strftime etc, and when I attempted to improve Time#strftime
performance, this problem showed up as the biggest bottleneck:
- https://github.com/ruby/ruby/pull/11547
- https://github.com/ruby/ruby/pull/11544
- https://github.com/ruby/ruby/pull/11542
Proposed API¶
I think a more effcient way to do this would be to work with a native buffer, and then build a RString
that "adopt" the memory region.
Technically, you can currently do this by reaching directly into RString members, but I don't think it's clean,
and a dedicated API would be preferable:
/**
* Similar to rb_str_new(), but it adopts the pointer instead of copying.
*
* @param[in] ptr A memory region of `capa` bytes length. MUST have been allocated with `ruby_xmalloc`
* @param[in] len Length of the string, in bytes, not including the
* terminating NUL character, not including extra capacity.
* @param[in] capa The usable length of `ptr`, in bytes, including the
* terminating NUL character.
* @param[in] enc Encoding of `ptr`.
* @exception rb_eArgError `len` is negative.
* @return An instance of ::rb_cString, of `len` bytes length, `capa - 1` bytes capacity,
* and of `enc` encoding.
* @pre At least `capa` bytes of continuous memory region shall be
* accessible via `ptr`.
* @pre `ptr` MUST have been allocated with `ruby_xmalloc`.
* @pre `ptr` MUST not be manually freed after `rb_enc_str_adopt` has been called.
* @note `enc` can be a null pointer. It can also be seen as a routine
* identical to rb_usascii_str_new() then.
*/
rb_enc_str_adopt(const char *ptr, long len, long capa, rb_encoding *enc);
An alternative to the adopt term, could be move.
Files
| Capture d’écran 2024-12-11 à 11.03.08.png (250 KB) Capture d’écran 2024-12-11 à 11.03.08.png | byroot (Jean Boussier), 12/11/2024 10:03 AM |
") Updated by Eregon (Benoit Daloze) over 1 year ago
Actions
#1
[ruby-core:119813]
Updated by Eregon (Benoit Daloze) over 1 year ago
Actions
#1
[ruby-core:119813]
LGTM, +1.
Maybe simply rb_str_adopt() for the name?
That way it's closer to rb_str_new(), and these days all String C API taking a C string should also take an encoding anyway so we don't need enc_ and enc-less variants.
") Updated by byroot (Jean Boussier) over 1 year ago
Actions
#2
[ruby-core:119815]
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#2
[ruby-core:119815]
Maybe simply rb_str_adopt() for the name?
I don't have a strong opinion here, I just went with the current convention.
On another note:
ptrMUST have been allocated withruby_xmalloc.
I'm actually not sure this really need to be a MUST, I suppose what is a MUST is that the pointer should be freeable with ruby_xfree, but that's it.
") Updated by nobu (Nobuyoshi Nakada) over 1 year ago
Actions
#3
[ruby-core:119816]
Updated by nobu (Nobuyoshi Nakada) over 1 year ago
Actions
#3
[ruby-core:119816]
I think it is unsafe for memory leak, in comparison with "RString allocated memory".
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#4
[ruby-core:119819]
I think it is unsafe for memory leak, in comparison with "RString allocated memory".
I'm sorry I don't follow, could you expand on what you mean is unsafe? The entire "adopt" idea?
") Updated by shyouhei (Shyouhei Urabe) over 1 year ago
Actions
#5
[ruby-core:119828]
Updated by shyouhei (Shyouhei Urabe) over 1 year ago
Actions
#5
[ruby-core:119828]
byroot (Jean Boussier) wrote in #note-4:
I think it is unsafe for memory leak, in comparison with "RString allocated memory".
I'm sorry I don't follow, could you expand on what you mean is unsafe? The entire "adopt" idea?
There is no reason for us to believe that the const char *ptr was allocated by malloc. It could be done by mmap or dlopen or anything. Ruby cannot garbage collect the string because it simply doesn't know how. Memory leak here is kind of inevitable.
Updated by nobu (Nobuyoshi Nakada) over 1 year ago
Actions
#6
[ruby-core:119830]
byroot (Jean Boussier) wrote in #note-4:
I think it is unsafe for memory leak, in comparison with "RString allocated memory".
I'm sorry I don't follow, could you expand on what you mean is unsafe? The entire "adopt" idea?
Whenever you allocate a new object, there is a risk of a memory error.
In that case, who will look after the pointer that is about to be "adopted"?
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#7
[ruby-core:119834]
There is no reason for us to believe that the const char *ptr was allocated by malloc.
The proposed function documentation state that the pointer MUST have been allocated with ruby_xmalloc.
henever you allocate a new object, there is a risk of a memory error. In that case, who will look after the pointer that is about to be "adopted"?
I see. From my understanding, the only possible error is OutOfMemory, what if rb_enc_str_adopt would directly call ruby_xfree on the pointer in such case? Would that cover your concern?
Updated by shyouhei (Shyouhei Urabe) over 1 year ago
Actions
#8
[ruby-core:119835]
byroot (Jean Boussier) wrote in #note-7:
There is no reason for us to believe that the const char *ptr was allocated by malloc.
The proposed function documentation state that the pointer MUST have been allocated with
ruby_xmalloc.
If that's okay that's okay. For instance a return value of asprintf cannot be "adopt"ed then because obviously, that's not allocated by ruby_xmalloc.
") Updated by rhenium (Kazuki Yamaguchi) over 1 year ago
Actions
#9
[ruby-core:119836]
Updated by rhenium (Kazuki Yamaguchi) over 1 year ago
Actions
#9
[ruby-core:119836]
byroot (Jean Boussier) wrote:
Work inside RString allocated memory¶
[...]
The downside with this approach is that it contains a lot of inefficiencies, asrb_str_set_lenwill perform
numerous safety checks, compute coderange, and write the string terminator on every invocation.
I thought rb_str_set_len() was supposed to be the efficient alternative to rb_str_resize() meant for such a purpose.
I think an assert on the capacity or filling the terminator is cheap enough that it won't matter. That it computes coderange is news to me - I found it was since commit 6b66b5fdedb2c9a9ee48e290d57ca7f8d55e01a2 / [Bug #19902] in 2023. I think correcting coderange after directly modifying the RString-managed buffer is the caller's responsibility. Perhaps it could be reversed?
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#10
[ruby-core:119840]
If that's okay that's okay. For instance a return value of asprintf cannot be "adopt"ed then because obviously, that's not allocated by ruby_xmalloc.
Yes, that's why I'm wondering if this requirement should be relaxed to "MUST be freeable by ruby_xfree", which I believe would be true for asprintf.
I think an assert on the capacity or filling the terminator is cheap enough that it won't matter.
It seemed to matter when I profiled. In some cases like strftime the string is written byte by byte, so it basically double the cost of appending a byte.
") Updated by kddnewton (Kevin Newton) over 1 year ago
Actions
#11
[ruby-core:119847]
Updated by kddnewton (Kevin Newton) over 1 year ago
Actions
#11
[ruby-core:119847]
I would use this in Prism as well. There are many cases where we allocate a string in the parser and then when we reify the Ruby AST we have to copy the string over. But the string content was allocated with ruby_xmalloc. So it would be nice to just hand over the string content without having to make a copy.
Personally I would prefer move as a naming convention, just because it mirrors what I would expect from std::move.
") Updated by mdalessio (Mike Dalessio) over 1 year ago
Actions
#12
[ruby-core:119848]
Updated by mdalessio (Mike Dalessio) over 1 year ago
Actions
#12
[ruby-core:119848]
This would likely be useful in Nokogiri as well. The two key places I have in mind are
- returning a large serialization string generated within libxml2 (which is configured to use
ruby_xmallocby default) - assembling an HTML5-compliant serialization within the extension (which currently uses
rb_enc_str_buf_cat)
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#13
[ruby-core:119982]
Proposed implementation: https://github.com/ruby/ruby/pull/12143
Updated by nobu (Nobuyoshi Nakada) over 1 year ago
Actions
#14
[ruby-core:119989]
Rather I want to propose an opposite:
char *rb_str_new_buffer(volatile VALUE *new_string, long size, rb_encoding *enc);
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#15
[ruby-core:119990]
How would that work? e.g. when you need to resize it?
Updated by nobu (Nobuyoshi Nakada) over 1 year ago
Actions
#16
[ruby-core:120148]
byroot (Jean Boussier) wrote in #note-15:
How would that work? e.g. when you need to resize it?
VALUE string;
char *buffer = rb_str_new_buffer(&string, size, enc);
memcpy(buffer, somestring, length);
// ...
rb_str_modify_expand(string, 10); // expand 10 bytes
buffer = RSTRING_PTR(string); // re-get the pointer
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#17
[ruby-core:120152]
Right, so that's not really different from https://bugs.ruby-lang.org/issues/20878#Work-inside-RString-allocated-memory. IT's something that's already done, that new function would just be a shortcut for:
VALUE str = rb_str_buf_new(capa);
char *buffer = RSTRING_PTR(str);
Updated by nobu (Nobuyoshi Nakada) over 1 year ago
Actions
#18
[ruby-core:120170]
Yes, and enc.
Finally you want to allocate the String for a String-manageable pointer, why not allocate a managing String from the beginning?
Updated by byroot (Jean Boussier) over 1 year ago
· Edited
Actions
#19
[ruby-core:120175]
why not allocate a managing String from the beginning?
I explained it in the issue body. If you want to append one character to an RString, you need something like:
void
buf_append_c(VALUE buf, char c)
{
long capa = rb_str_capacity(buf);
if (RSTRING_LEN(buf) + 1 > capa) {
rb_str_modify_expand(buf, capa); // double capa
}
char *ptr;
long len;
RSTRING_GETMEM(buf, ptr, len);
ptr[len] = c;
// Lenght must be set right away in case GC
// triggers and tries to re-embed the buffer.
rb_str_set_len(buf, len + 1);
}
First that a lot more complicated than just working with a raw malloced buffer, you need some pretty good knowledge of Ruby inner workings not to make a mistake. For example, you could save some metadata like capacity, but any time GC triggers, it's potentially no longer valid.
Second, all the rb_str_* function will do a lot of costly sanity checking.
If I profile a simple script that's calling Time#strftime, which is internally using the APIs you suggest:
time = Time.now
i = 10_000_000
while i > 0
i -= 1
time.strftime("%FT%T.%6N")
end
It looks like this: https://share.firefox.dev/3ZNdAfg
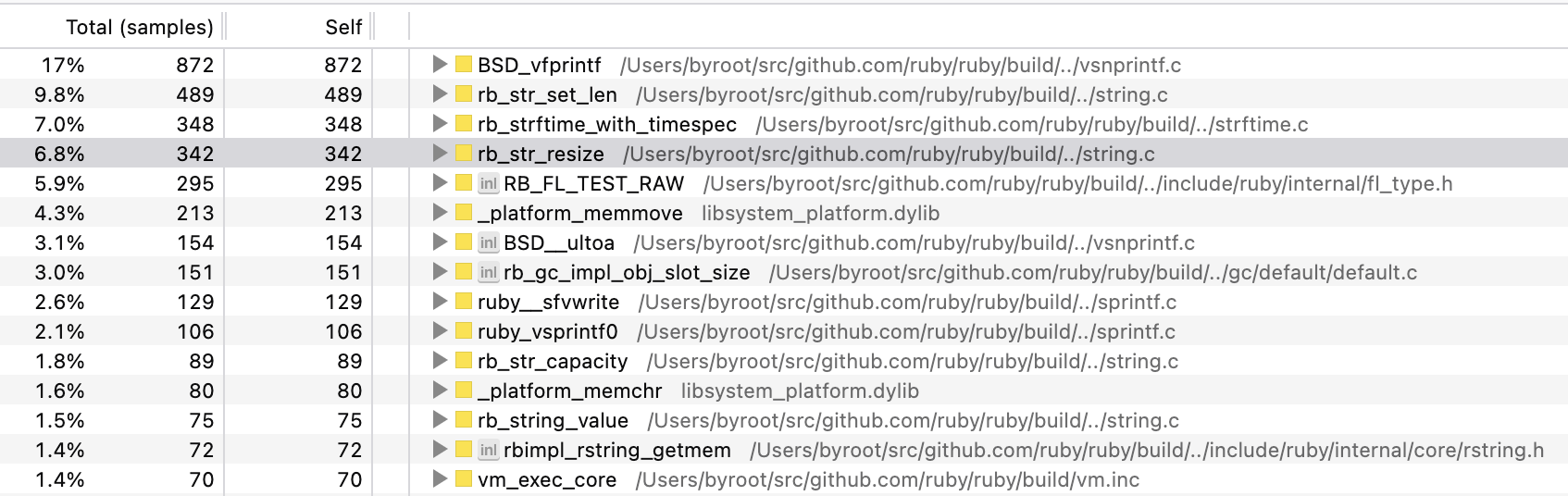
A ton of time is spent in:
-
rb_str_set_len(9.8%) -
rb_str_resize(6.8%) -
RB_FL_TEST_RAW(to getRSTRING_PTRetc) (5.9%)
All together, that's more than the time spent doing the actual formatting work in BSD_vfprintf, this seems like a major overhead to me.
If at least the API was easier to work with, I wouldn't mind so much, but in my opinion it's actually harder to work with.
Updated by nobu (Nobuyoshi Nakada) over 1 year ago
Actions
#20
[ruby-core:120197]
byroot (Jean Boussier) wrote in #note-19:
why not allocate a managing String from the beginning?
I explained it in the issue body. If you want to append one character to an RString, you need something like:
It is same as rb_str_cat(buf, &c, 1).
First that a lot more complicated than just working with a raw malloced buffer, you need some pretty good knowledge of Ruby inner workings not to make a mistake. For example, you could save some metadata like
capacity, but any time GC triggers, it's potentially no longer valid.
I can't get your point here.
Your proposal does need the knowledge more, I think.
A ton of time is spent in:
rb_str_set_len(9.8%)rb_str_resize(6.8%)RB_FL_TEST_RAW(to getRSTRING_PTRetc) (5.9%)All together, that's more than the time spent doing the actual formatting work in
BSD_vfprintf, this seems like a major overhead to me.
Recursive format in Time#strftime may have a room for improvement.
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#21
[ruby-core:120202]
It is same as rb_str_cat(buf, &c, 1).
Yes and:
- You can't always use
rb_str_cat, sometimes you have to pass a pointer to an existing API. -
rb_str_catdoes all the checks I mentioned and even more.
I can't get your point here.
I'm proposing a way to build strings that is both more convenient and more efficient.
The typical use case being ruby/json fbuffer.h and similar buffers in other gems such as msgpack etc.
") Updated by mame (Yusuke Endoh) over 1 year ago
Actions
#22
[ruby-core:120206]
Updated by mame (Yusuke Endoh) over 1 year ago
Actions
#22
[ruby-core:120206]
Discussed at the dev meeting.
Yes, that's why I'm wondering if this requirement should be relaxed to “MUST be freeable by ruby_xfree”, which I believe would be true for asprintf.
No, ruby_xfree is not a simple delegator to system free, depending on environment and configuration.
However, in many environments (at the moment), it only delegates to system free, so it would be very hard to notice if it inadvertently depends on the implementation. This proposed API risks promoting such misuse.
So, it must be proved that this API is really unavoidable. We would like you to try to use String objects as buffers instead of memory pointer. If that brings performance problems, consider again.
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#23
[ruby-core:120208]
We would like you to try to use String objects as buffers instead of memory pointer.
Yes, I was planning to try to convert JSON's fbuffer to use RString to show the impact. I'll update here once I have a working implementation.
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#24
[ruby-core:120216]
Done: https://github.com/byroot/json/pull/1
It's basically twice as slow on almost all benchmarks. My implementation is rather naive, I'm sure a bit of performance can be reclaimed by using various tricks, but it's risky as you have to be careful when GC trigger and kinda defeat the purpose of using a higher level API.
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#25
[ruby-core:120220]
No, ruby_xfree is not a simple delegator to system free, depending on environment and configuration.
I see, I didn't know about that compilation flag, thanks for letting me know that.
One solution I see (but that I'm not very fond of) is to pass the free function that must be used to adopt, e.g.
str = rb_enc_str_adopt(buf->ptr, buf->len, buf->capa, rb_utf8_encoding(), ruby_xfree);
// or
str = rb_enc_str_adopt(buf->ptr, buf->len, buf->capa, rb_utf8_encoding(), free);
This way rb_enc_str_adopt can check if adopting the string is legal, and if it isn't deoptimize it into a copy?
Updated by rhenium (Kazuki Yamaguchi) over 1 year ago
Actions
#26
[ruby-core:120228]
byroot (Jean Boussier) wrote in #note-19:
First that a lot more complicated than just working with a raw malloced buffer, you need some pretty good knowledge of Ruby inner workings not to make a mistake. For example, you could save some metadata like
capacity, but any time GC triggers, it's potentially no longer valid.
I think I understood what you meant. From what I remember, compaction should exclude objects pinned by rb_gc_mark() or referenced from the machine stack. In the Time#strftime example, much fewer rb_str_set_len() calls should be necessary since the String would be always on the stack.
Perhaps a more explicit way to prevent the re-embedding should be provided (for example by having the compaction code check the rb_str_locktmp() status).
The proposed API seems tricky to me in that it requires the user to allocate a buffer including the terminator length. The NUL terminator is an implementation detail left out from the public API so far, and I believe it's something we've wanted to eventually get rid of for the SHARABLE_MIDDLE_SUBSTRING optimization. I'm not sure if exposing it is a good idea.
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#27
[ruby-core:120229]
I think I understood what you meant. From what I remember, compaction should exclude objects pinned by rb_gc_mark() or referenced from the machine stack.
You are correct.
In the Time#strftime example, much fewer rb_str_set_len() calls should be necessary since the String would be always on the stack.
I don't think many of these could really be eluded, because you need to call it before every other call to a rb_str_ method, e.g:
// from strftime.c
rb_str_set_len(ftime, s-start); // must set the length before calling rb_str_append
rb_str_append(ftime, tmp);
RSTRING_GETMEM(ftime, s, len); // rb_str_append have changed the length and potentially the pointer.
The NUL terminator is an implementation detail left out from the public API so far [...] I'm not sure if exposing it is a good idea.
That's a very good point. I think it could be rephrased to say the NUL terminator is optional. Given the pointer is semantically adopter as soon as the function is called, it could do a realloc is needed to add the terminator. Making it an implementation detail.
Updated by shyouhei (Shyouhei Urabe) over 1 year ago
Actions
#28
[ruby-core:120292]
One thing pointed out in the last developer meeting was that future MMTK might want to break "asprintf return values can be reclaimable using ruby_xfree" assumption at process startup, by choosing different memory management schemes.
Updated by mame (Yusuke Endoh) over 1 year ago
Actions
#29
[ruby-core:120516]
Thanks for the benchmark. I briefly talked about this with @nobu (Nobuyoshi Nakada), @akr (Akira Tanaka), and @ko1 (Koichi Sasada).
The approach of passing a pointer to the free function looks a bit too over-the-top, @nobu (Nobuyoshi Nakada) said.
It need not only free function but also realloc function, @akr (Akira Tanaka) said.
I think it would be easy to just strictly keep the prerequisite “ptr MUST have been allocated with ruby_xmalloc.” as originally proposed.
Is there a real-world use case to make a String with a pointer allocated outside of xmalloc?
@ko1 (Koichi Sasada) suggested to introduce this API as a hidden API only for json gem, instead of introducing it as an official one.
Updated by byroot (Jean Boussier) over 1 year ago
Actions
#30
[ruby-core:120518]
It need not only free function but also realloc function
Maybe I wasn't clear, but I my suggestion is to only use the free function to detect if it's compatible with ruby_xfree, which we presumbably can know at compile time, so something like:
rb_enc_str_adopt(const char *ptr, long len, long capa, rb_encoding *enc, void * freefunc(void *))
{
if (freefunc != ruby_xfree && (CALC_EXACT_MALLOC_SIZE || freefunc != free)) {
// copy and return
}
else {
// adopt the pointer
}
}
We could also use the malloc function instead for the same effect.
Is there a real-world use case to make a String with a pointer allocated outside of xmalloc?
I don't personally have one, ``snprintfwas mentioned, and it seems realistic? Butsnprintf` buffer generally aren't that big, so maybe it doesn't matter as much?
Also perhaps @mdalessio (Mike Dalessio) would have some in nokogiri?
suggested to introduce this API as a hidden API only for json gem, instead of introducing it as an official one.
I don't think it would be a good precedent, given json is only a default gem. Also both nokogiri and prism maintainers expressed their interest.
I think it would be easy to just strictly keep the prerequisite “ptr MUST have been allocated with ruby_xmalloc.” as originally proposed.
I'm also OK with that.
Updated by mdalessio (Mike Dalessio) over 1 year ago
· Edited
Actions
#31
[ruby-core:120522]
Is there a real-world use case to make a String with a pointer allocated outside of xmalloc?
I don't personally have one..
Also perhaps @mdalessio (Mike Dalessio) (Mike Dalessio) would have some in nokogiri?
Yes, it would be easiest for Nokogiri if non-xmalloc string pointers were supported, but if it was decided to not support this, I would be OK with it.
Nokogiri actively configures libxml2's memory management functions. On windows, libxml2 is configured to use malloc because of bugs in some versions of libxml2. 1 On other platforms, Nokogiri configures libxml2 to use ruby_xmalloc by default, but users can opt into using malloc, for example if they want to optimize performance and don't mind having a larger max heap size. 2
But! If anyone is opting into using malloc, it is likely for performance reasons. If the performance improvement from pointer adoption is great enough, and malloc strings are not supported, then I would consider removing the feature.
On windows, the libxml2 bugs have been fixed for three years (fixed 2022-02 in v2.9.13 3) and most windows developers are using the precompiled native gem anyway, so if I have to, I would be comfortable changing the default to be ruby_xmalloc on windows or working around the limitation in pointer adoption.