Feature #19458
open")
Expose HEREDOC identifier
Description
I’d like to have access to the HEREDOC identifier.
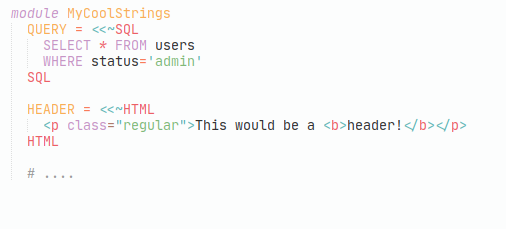
In the ViewComponent framework I help maintain, we added a method to declare a template as such:
I'd prefer to be able to write:
And be able to see that the argument passed to .template was from a HEREDOC with an ERB identifier, which would allow me to use the correct template handler to compile the template.
I could see this being implemented:
- As a new property of String, such as
identifierorheredoc_identifier. - By having HEREDOCs return a subclass of String that includes an
identifierproperty.
I'd be happy to work on implementing this change.
Files
") Updated by sawa (Tsuyoshi Sawada) over 3 years ago
Updated by sawa (Tsuyoshi Sawada) over 3 years ago
To my understanding, the reason you can freely choose the heredoc identifier is not to label the language of the content, but to allow any string to appear in it. In your example, if you had a line within your string that is just ERB besides spaces, you need to come up with an identifier that is different from ERB (as well as any other line in your string). That is what the freedom of the identifier is for.
The purpose of an identifier is just to terminate a string, and it should not carry any significant information. Some editors can hilight the contents of heredoc in different languages depending on the identifier, but that is out of the scope of Ruby, and that only works probabilistically, i.e., under the assumption that you will probably not so often have a line that is identical to the identifier in question. Whether the heredoc identifier is ERB, MD, or _ is no more significant than whether the string was written as "...", '...', ?x, %q{...}, or %Q|...|, etc.
Relying on the heredoc identifier to infer the language is also not clean. If you need to notify the method of the language as well as the string, you should pass two arguments: perhaps a symbol representing the language, and the string.
") Updated by zverok (Victor Shepelev) over 3 years ago
Updated by zverok (Victor Shepelev) over 3 years ago
I came to the same idea as this ticket independently in a half-joke discussion, and I find it tempting, too. Even planned to submit my own proposal once I'll have it clearly formed in my head.
To my understanding, the reason you can freely choose the heredoc identifier is not to label the language of the content, but to allow any string to appear in it.
First, there is quite widespread agreement to use embedded language's name as a heredoc identifier. So widespread, in fact, that many editors give it as a hint for highlighting:
(SublimeText's standard Ruby highlighting.)
Second, even ignoring this argument, the delimiter of HEREdoc is "user's data," so it is up to the user to know what it means, and it is frequently meaningful for them, so programmatic access to this information might be valuable for many contexts. Of course, many users do some "regular" stuff (like STR or EOS), but others use the possibility to "tag" strings, and if Ruby will give the access to this "tag", it might find many good usages.
Updated by sawa (Tsuyoshi Sawada) over 3 years ago
@zverok (Victor Shepelev) So what are you supposed to do if you wanted to include ERB in the string when you have to use ERB as the identifier? Did you fully read my comment? By the way, your first point is exactly what I mentioned.
Updated by zverok (Victor Shepelev) over 3 years ago
So what are you supposed to do if you wanted to include ERB in the string when you have to use ERB as the identifier?
This is a valid concern, and it doesn't have any good answer to it.
On the other hand,
- the possibility of a need to have a literal text
ERB/HTML/SQL/SLIMon a separate line in a HEREdoc presumably written in the corresponding language is relatively low ( - the feature of "there could be any text" was indeed introduced for a use cases you are describing, but its real usage for "tagging" strings is quite widespread; saying that it is no more significant than
"vs'follows the original intention, but ignores the real usage (including in Ruby's standard library codebase, for example). - the usefulness of acknowledging "tagging" use in a language seems to be a least worth a discussion; whereupon the harm of this idea seems to be quite low (other than the general opposition to change).
") Updated by jeremyevans0 (Jeremy Evans) over 3 years ago
Updated by jeremyevans0 (Jeremy Evans) over 3 years ago
Exposing the identifier for only heredocs seems inconsistent. However, for consistency, we could expose the identifier for all literal Ruby strings:
'foo'.identifier # => "'"
"foo".identifier # => "\""
%[foo].identifier # => "%["
%q{foo}.identifier # => "%q{"
%Q|foo|.identifier # => "%Q|"
?f.identifier # => "?"
For strings created via the C-API, identifier would return nil. This could result in interesting applications.
That being said, I'm against the adding such a method. I do see the advantage in avoiding redundancy, but it seems a specialized case, and not something worth adding a core method for.
Updated by zverok (Victor Shepelev) over 3 years ago
My thinking (the proposal I considered submitting but didn't fully form yet) was rather that HEREdocs might create some subclass, like TaggedString or something (which might also be able to create by other means, say, literally TaggedString.new(content, tag: :ERB)), and that might create some interesting consequences, too.
Not sure yet if I'll ever submit this one; just thinking about it and trying to understand whether it is of generic use.
TBH, "whether it was created with ' or "" (while also "might be useful") doesn't seem to be of the same level of interest/importance as custom text entered to delimit a HEREdoc.
") Updated by rubyFeedback (robert heiler) over 3 years ago
Updated by rubyFeedback (robert heiler) over 3 years ago
I have no particularly strong opinion either way.
But I wanted to comment on zverok's statement:
[...] use the possibility to "tag" strings, and if Ruby
will give the access to this "tag", it might find many
good usages.
I agree somwhat with that opinion too.
For instance, I also suggested to propose an extension to case/when
"interfaces" where we can not only access all case/when entries in
a given method (perhaps only for non-private methods), and merge
different case/when entries, as well as adding methods such as
.to_h or .to_hash to convert it to a hash, and/or to a proc object,
and .call() on it.
My original use case for this, several years ago, was to be able to
autogenerated tab-completion for shells such as bash and zsh. So
that I can know all entries in a case/when menu. For instance:
case x
when 'a','b','c'
'foobar' # all three match to foobar, similar to a Hash where the
# three keys 'a','b' and 'c' would point to 'foobar'
end
Since then case/when menu got even better support - see pattern
matching.
Anyway - making a good proposal that is not-trivial, is quite difficult
actually, so I kind of dropped it, hoping that someone else may find the
motivation to do a good proposal here one day. :D
So, to come to this issue - I think if you look at it from an extended
point of view, then being able to know associated use cases could indeed
be interesting, so on that topic I concur with zverok. That does not
mean I am in favour of the suggestion here, or in disfavour - I just think
it may indeed be worthy to explore use case here. I have not had a huge
need to use ERB per se, but I do happen to read in a .md file that I then
evaluate as if it were ruby code (and pass to an object that evaluates
the content of this file), so this is a bit similar to ERB. What annoys me
a bit is that I can not get as accurate information where an error happens,
because I read in that file. For instance, just to explain that, I have
error messages such as:
(eval):23:in `header': wrong number of arguments (given 5, expected 0..2) (ArgumentError)
from /usr/lib/ruby/site_ruby/3.2.0/foobar/web_stuff/misc.rb:317:in `clickable_header'
from (eval):530:in `block (2 levels) in evaluate_from_this_file'
from /usr/lib/ruby/site_ruby/3.2.0/foobar/web_stuff/html_tags.rb:512:in `div'
from /usr/lib/ruby/site_ruby/3.2.0/foobar/web_stuff/misc.rb:3718:in `doc'
from (eval):30:in `block in evaluate_from_this_file'
from /usr/lib/ruby/site_ruby/3.2.0/foobar/web_stuff/misc.rb:3194:in `instance_exec'
from /usr/lib/ruby/site_ruby/3.2.0/foobar/web_stuff/misc.rb:3194:in `handle_these_calls'
from /usr/lib/ruby/site_ruby/3.2.0/foobar/web_stuff/english.rb:25:in `english'
from (eval):1:in `evaluate_from_this_file'
And it is a bit difficult to trace back the error specifically when I read in such a
file. At any rate, I think the underlying idea, even if not implemented, should not be
dismissed too easily.
") Updated by joelhawksley (Joel Hawksley) over 3 years ago
Updated by joelhawksley (Joel Hawksley) over 3 years ago
zverok (Victor Shepelev) wrote in #note-6:
My thinking (the proposal I considered submitting but didn't fully form yet) was rather that HEREdocs might create some subclass, like
TaggedStringor something (which might also be able to create by other means, say, literallyTaggedString.new(content, tag: :ERB)), and that might create some interesting consequences, too.
Given the feedback here so far, this is the approach I think we should take.
") Updated by janosch-x (Janosch Müller) about 3 years ago
Updated by janosch-x (Janosch Müller) about 3 years ago
sawa (Tsuyoshi Sawada) wrote in #note-3:
@zverok (Victor Shepelev) So what are you supposed to do if you wanted to include
ERBin the string when you have to useERBas the identifier?
Updated by janosch-x (Janosch Müller) about 3 years ago
joelhawksley (Joel Hawksley) wrote in #note-8:
My thinking (the proposal I considered submitting but didn't fully form yet) was rather that HEREdocs might create some subclass, like
TaggedString[...]Given the feedback here so far, this is the approach I think we should take.
That would be a substantial breaking change for a minor feature. It would break code like foo.class == String or foo.instance_of?(String).
") Updated by Dan0042 (Daniel DeLorme) almost 3 years ago
Updated by Dan0042 (Daniel DeLorme) almost 3 years ago
What about something as KISS as possible, like just adding an instance variable to heredoc strings.
string.instance_variable_get(:@heredoc) == :ERB
") Updated by bradgessler (Brad Gessler) about 2 years ago
· Edited
Updated by bradgessler (Brad Gessler) about 2 years ago
· Edited
I'm working with some code in Phlex that would benefit from introspecting the name of the HEREDOC. Here's what I currently have:
ContentSlide(title: "Why Phlex?"){
Markdown <<~MARKDOWN
* Because its fun
* Because its super-de-dooper
MARKDOWN
}
The Markdown <<~MARKDOWN line feels like it came from the redundancy department of redundancy. I would do this:
But there's no %{} type blocks that deal with indents like HEREDOCS.
I like Jeremy's proposal of an identifier method.